
AI for Good, at Scale?
May 2, 2019 — The Big Picture
Below is an extract from Trent McConaghy’s article, which explores how “AI for Good” can be scaled to address the UN Sustainable Development Goals. One approach is to close the gap between problem owners and problem solvers using blockchain public utility network.
It was originally published on April 22, 2019, by Ocean Protocol.
To read the full version, click here.
Connecting Problem Owners with Problem Solvers
The Gap
If you’re a first year AI PhD student, you’re usually given a data/problem set to work with, such as ImageNET for computer vision, or UCI Repository, or OpenML. More often than not, you’re not connected to the people with the actual problem. This was even my experience, 20 years ago. And very rarely are you connected to people with impact problems like the UN Sustainable Development Goals. This disconnect often doesn’t disappear as students progress through their PhD and career.
In the context of the funnel, this issue is framed as linking steps 1 and 2. There’s a gap between the people with the challenges (problem owners) and the people with the expertise to solve the problems (problem solvers).
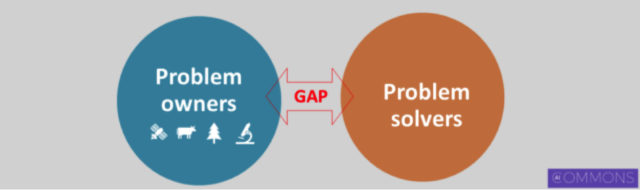
The problem owners have the AI-type problems to solve at step 1, such as tracking deforestation or cattle movement. The problem solvers are the data scientists and AI researchers, who can build the AI prototypes at step 2.
There are two complementary solutions to help solve this:
- Human-based approaches
- Connective substrate technology
I’m excited about both! The former is about AI researchers getting out of the office and into the field, for meaningful face-to-face interactions; along with systematic ways to capture the problem definition towards solving it. The “field” could be local to the AI researcher, or it could be farther away. I see that AI for Good opportunities can exist anywhere, so why not start local?
The latter is about using technology as a global connective substrate. The next section elaborates.
Connective Substrate Technology
First, we flesh out the ecosystem with other key actors. The image below illustrates.
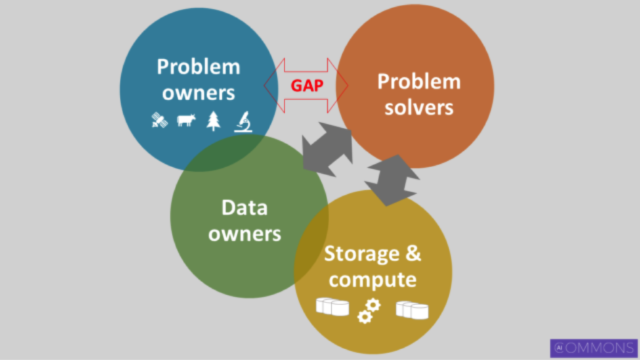
Most modern AI applications are about building classification and regression models. These models love data. The data is held by the data owners. The data owners are usually talking to the problem owners, at least a bit.
Then there’s also the storage of the data itself, and the compute by the problem solver to train the models. And the high-level goal remains the same: we’re helping connect problem solvers with problem owners to solve the AI problems.
The idea is to create a connective substrate to make it easier for data owners, storage and compute, problem owners, and problem solvers to connect and to solve problems. It should be a public utility, not owned or controlled by anyone.
We’ve had public utility networks for a long time, like the public water system, the electric grid, and the internet. Some public utility networks sit on top of the internet base layer, including the World Wide Web and the Bitcoin blockchain network. Blockchain technology is the appropriate choice to implement our public utility network to connect problem owners, problem solvers, and the rest.
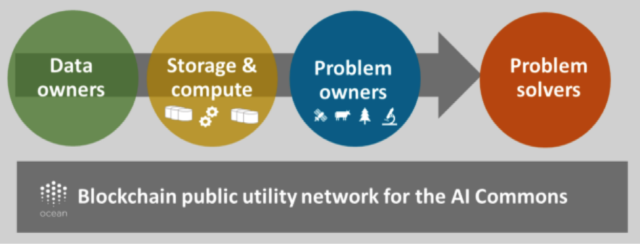
Let’s further flesh out what this blockchain-based public utility network actually looks like.
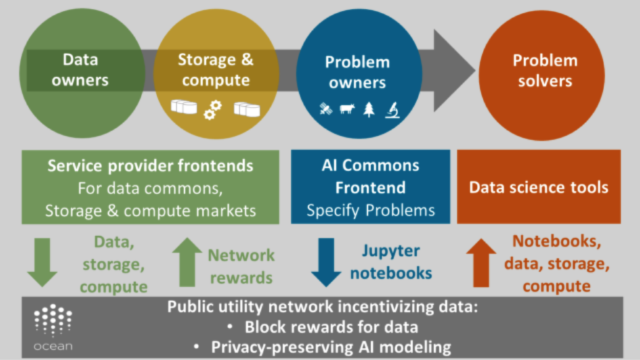
Data, storage, compute (top left). Data owners interact with different service provider frontends which in turn connect to the public utility network. There are also suppliers of storage and compute services, interacting through markets to buy and sell the services. In return for data and services, they get paid by people on the demand side. That’s for paid data. We also want to incentivize people to supply data to the commons, which in turn will spread the benefits of data and therefore the benefits of AI. To implement this, the network itself pays people to supply data to the commons, using inflation.
Finally, we can unlock private data by bringing compute to the data. In this fashion, the private data never leaves the premises, yet AI models can be built from it.
AI Commons frontend (top middle). In the AI Commons frontend, problem owners specify the problems and work closely with problem solvers. There’s a back and forth between solving the problem, and defining the problem with more clarity. Problem owners can define the problem in interactive notebooks such as Jupyter.
Problem solvers (top right). Problem solvers take as input a problem from the network (e.g. Jupyter) and start to solve it. They draw on data, compute and storage services. Their progress is recorded in the network, giving provenance to the compute and data. Their final result is also stored in the network, for example as a Jupyter notebook.
Problem specification and problem solving is an incremental process: do an initial specification of problem, do a first-cut solution (perhaps with automated ML), then take the learnings from the initial solution to refine or change the problem, do a second-round solution, and so on. This also implies that the boundary for tools for problem specification and problem solving will blur. For example, AI Commons frontends will evolve towards including solutions.